一、概念
1.1 同步
为了避免多个线程同时读写同一个数据而产生不可预料的后果,我们要将各个线程对同一个数据的访问同步(Synchronization)。
所谓同步,即指在一个线程访问数据未结束的时候,其他线程不得对同一个数据进行访问。如此,对数据的访问被原子化了。
同步最常见的方法是使用锁(Lock)。
1.2 锁
锁是一种非强制机制,每一个线程在访问数据或资源之前首先试图获取(Acquire)锁,并在访问结束之后释放(Release)锁。在锁已经被占用的时候试图获取锁时,线程会等待,直到锁重新可用。
二、类型
在计算机开发中,锁通常有3大类:自旋锁、互斥锁、条件锁。
2.1 自旋锁(SpinLock)
特点
线程反复检查变量是否可用。由于线程在这一过程中保持执行,因此属于忙等待。一旦获取了自旋锁,线程会一直保持该锁,直至显式释放自旋锁。自旋锁避免了进程上下文的调度开销,因此对于线程只会阻塞很短时间的场合是有效的。
例子
- OSSpinLock 因为线程安全,现已被废弃
2.2 互斥锁(Mutex)
特点
防止两条线程同时对同一公共资源进行读写的机制。通过将代码切片成一个个临界区而实现。
例子
- pthread_mutex
- @synchronized
- NSLock
- os_unfair_lock
2.3 条件锁(Condition Variable)
特点
作为一种同步手段,作用类似一个栅栏。当进程的某些资源要求不满足就进入休眠,也就是锁住。当资源被分配到了,条件锁打开,进程继续进行。
例子
- NSCondition
- NSConditionLock
2.4 递归锁(recursive)
特点
同一个线程可以加锁N 次而不会引起死锁
例子
- NSRecursiveLock
- pthread_mutex(recursive)
2.5 信号量(Semaphore)
特点
允许多给写线程并发访问的资源,简称信号量,一个初始值为N的信号量允许N个线程并发放温。
线程访问资源时做以下操作:
- 信号值减1
- 如果信号值小于0,则进入等待状态,否则继续执行
线程访问完资源后,释放信号量时操作如下:
- 信号量得值加1
- 如果信号量的值小于1,唤醒一个等待中的线程
例子
- dispatch_semaphore
三、常见锁分析
3.1 递归锁 - @synchronized分析
3.1.1 引子
先编写 如下代码,并打开汇编诊断(Xcode中,Debug——Debug Flow——Always Show Dissembly)
@synchronizedd (self) { |
得到如下调用栈:
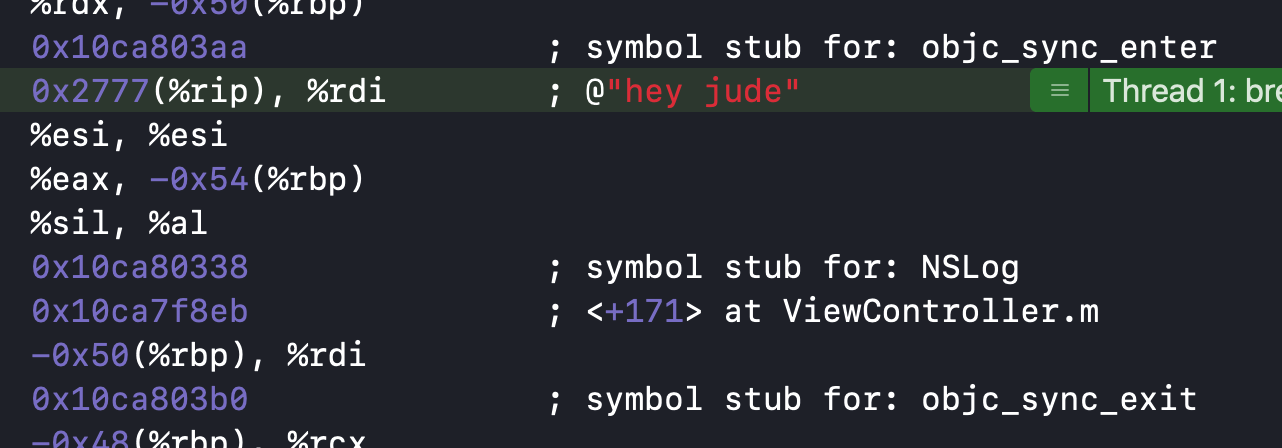
留意到有objc_sync_enter 以及objc_sync_exit,进入退出一一匹配,猜测可能就是锁的加锁与解锁。先不管了,找到objc 开源库
3.1.2 objc_sync_enter
在objc4 中可以找到objc_sync_enter 函数,它的作用是:开始锁住obj,如有必要,开辟递归互斥锁关联到obj,一旦锁被获取到,返回OBJC_SYNC_SUCCESS的标识
// Begin synchronizing on ‘obj’.
// Allocates recursive mutex associated with ‘obj’ if needed.
// Returns OBJC_SYNC_SUCCESS once lock is acquired.
函数实现如下:
int objc_sync_enter(id obj) |
分析一下方法实现:
如果加锁目标对象不存在,不作操作
// @synchronizedd(nil) does nothing
if (DebugNilSync) {
_objc_inform("NIL SYNC DEBUG: @synchronizedd(nil); set a breakpoint on objc_sync_nil to debug");
}
objc_sync_nil();注释已经写得很清楚了,does nothing。继续看
objc_sync_nil如何实现BREAKPOINT_FUNCTION(
void objc_sync_nil(void)
);的确,啥也没干。这样也解释了某些场合下,锁一个空对象,是不会做操作的。
如果传入对象存在
if (obj) {
SyncData* data = id2data(obj, ACQUIRE);
ASSERT(data);
data->mutex.lock();防止死锁:这里的SyncData 拥有
next指向的递归锁结构,好处就是最终总会有 object 为 nil,会跳出循环,不会死锁。这里的好处就是最终总会有
object为nil,会跳出循环,防止死锁。typedef struct alignas(CacheLineSize) SyncData {
struct SyncData* nextData;
DisguisedPtr<objc_object> object;
int32_t threadCount; // number of THREADS using this block
recursive_mutex_t mutex;
} SyncData;里面有数据域:DisguisedPtr、threadCount、recursive_mutex_t,以及指针域:
SyncData* nextData继续看
id2data的实现如下:查询当前单一线程的快速缓存文件匹配。
如果有,对锁住的次数,根据传入参数类型(获取、释放、查看),分别进行操作。
- 如果是获取资源:锁次数++
- 如果是释放资源:锁次数–。当然如果次数变为0,此时锁也不复存在,需要从快速缓存移除。
- 如果是查看资源:不操作。
相关代码精简如下:
SyncData *data = (SyncData *)tls_get_direct(SYNC_DATA_DIRECT_KEY);
if (data){
uintptr_t lockCount;
switch(why){
case ACQUIRE: {
lockCount++;
case RELEASE:
lockCount--;
if (lockCount == 0) {
// remove from fast cache
tls_set_direct(SYNC_DATA_DIRECT_KEY, NULL);
case CHECK:
// do nothing
break;
}
}查询所有线程内部缓存文件与锁持有对象的匹配
首先会查找一个线程缓存
SyncCache,查找的过程是这样的(有精简):static SyncCache *fetch_cache(bool create)
{
_objc_pthread_data *data;
data = _objc_fetch_pthread_data(create);
/* 省略部分*/
// Make sure there's at least one open slot in the list.
if (data->syncCache->allocated == data->syncCache->used) {
data->syncCache->allocated *= 2;
data->syncCache = (SyncCache *)
realloc(data->syncCache, sizeof(SyncCache)
+ data->syncCache->allocated * sizeof(SyncCacheItem));
}
return data->syncCache;
}先创建一个
_objc_pthread_data类型的线程数据查看线程私有数据,如果有,就会更新
data接下来对同步缓存容量查看,如果使用已满(allocated == used),会进行 *2 扩建扩容
接下来将同步缓存返回
有意思的是这个
syncCache是专门针对@synchronized 准备的,如下图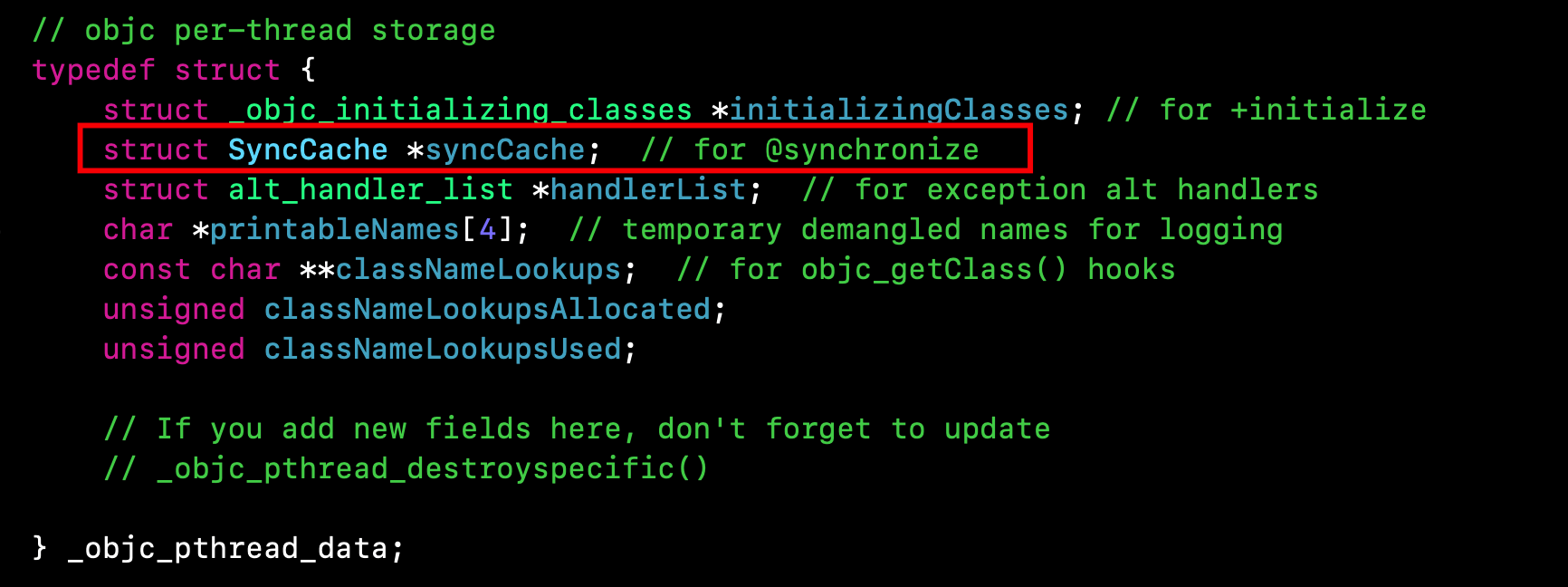
接下来根据缓存文件
SyncCache的存在,进行循环遍历,取出cache内的元素——SyncCacheItem结构体,根据传入参数类型(获取、释放、查看),进行内部属性,分别进行操作。如果是获取资源:锁次数++
case ACQUIRE:
item->lockCount++;=如果是释放资源:锁次数–。当然如果次数变为0,需要从线程缓存数据移除。
case RELEASE:
item->lockCount--;
if (item->lockCount == 0) {
// remove from per-thread cache
cache->list[i] = cache->list[--cache->used];如果是查看资源:不操作。
case CHECK:
// do nothing
去已使用列表查找匹配对象(快速、慢速缓存均未找到)
在介绍步骤之前,先普及一下已使用列表(in-use list) 的结构。在这个
id2data函数执行初始时,执行了两个代码static SyncData* id2data(id object, enum usage why)
{
spinlock_t *lockp = &LOCK_FOR_OBJ(object);
SyncData **listp = &LIST_FOR_OBJ(object);即生成了一个名为
lockp的自旋锁,以及SyncData指针对象。而LOCK_FOR_OBJ与LIST_FOR_OBJ是两个宏操作,如下:// Use multiple parallel lists to decrease contention among unrelated objects.
static StripedMap<SyncList> sDataLists;看得出都说在查找一个
sDataLists的列表元素的lock、data属性,这个表结构比较简单:struct SyncList {
SyncData *data;
spinlock_t lock;
constexpr SyncList() : data(nil), lock(fork_unsafe_lock) { }
};接下来重点关注一下
StripedMap这个类,可以成为条纹映射map,是一种结构void* -> T的map,有一个indexForPointer的函数,用来指向内部存储的对象——即缓存的syncData 对象static unsigned int indexForPointer(const void *p) {
uintptr_t addr = reinterpret_cast<uintptr_t>(p);
return ((addr >> 4) ^ (addr >> 9)) % StripeCount;
}好的,接下来看
先加锁
如果找到,添加到快速缓存以及线程内缓存里
if (!fastCacheOccupied) {
// Save in fast thread cache
tls_set_direct(SYNC_DATA_DIRECT_KEY, result);
tls_set_direct(SYNC_COUNT_DIRECT_KEY, (void*)1);
} else
{
// Save in thread cache
if (!cache) cache = fetch_cache(YES);
cache->list[cache->used].data = result;
cache->list[cache->used].lockCount = 1;
cache->used++;
}如果未找到,创建新的
data,并加入到datalist内部posix_memalign((void **)&result, alignof(SyncData), sizeof(SyncData));
result->object = (objc_object *)object;
result->threadCount = 1;
new (&result->mutex) recursive_mutex_t(fork_unsafe_lock);
result->nextData = *listp;
*listp = result;解锁
小结:这个查找锁的过程,很类似方法查找的过程,先通过缓存查找,接着在方法列表里查找,如果查找不到,会创建一个并加入到列表以及二级缓存中,进行返回。
对已获取的data 加锁
执行如下操作:
result = data->mutex.tryLock();
这里会返回这个tryLock 的实现是一个递归互斥锁的执行结果,具体实现如下:
bool tryLock()
{
if (os_unfair_recursive_lock_trylock(&mLock)) {
lockdebug_recursive_mutex_lock(this);
return true;
}
return false;
}
3.1.3 objc_send_exit
分析完了enter,再看看如何对@synchronized 如何离开。
函数主要操作是:
- 终止同步锁obj,
- 返回OBJC_SYNC_SUCCESS(成功) 或者OBJC_SYNC_NOT_OWNING_THREAD_ERROR(失败)
// End synchronizing on ‘obj’.
// Returns OBJC_SYNC_SUCCESS or OBJC_SYNC_NOT_OWNING_THREAD_ERROR
查看同步数据是否存在
主函数实现精简如下
SyncData* data = id2data(obj, RELEASE);
if (!data) {
result = OBJC_SYNC_NOT_OWNING_THREAD_ERROR;
} else {
bool okay = data->mutex.tryUnlock();
if (!okay) {
result = OBJC_SYNC_NOT_OWNING_THREAD_ERROR;
}
}如果锁列表里找不到obj,即加锁对象不存在,退出并报出对象同步未拥有的线程错误
如果有找到,尝试解锁
tryUnlock。这里的解锁也是递归锁的解锁,具体实现如下:bool tryUnlock()
{
if (os_unfair_recursive_lock_tryunlock4objc(&mLock)) {
lockdebug_recursive_mutex_unlock(this);
return true;
}
return false;
}如果解锁失败,也报出对象同步未拥有的线程错误
3.1.4 总结
- 针对pthread 进行了封装,体现在tls 的查找机制。
- @synchronized 分为高速缓存、线程内数据缓存(tls)以及已使用对象的列表进行加锁缓存
- 加锁为一个syncList 的列表,列表内有多个syncData 的对象
- 外界对加锁对象的获取/释放,会相应的对同步数据节点的属性+1/-1
- 优点:采用缓存机制,不会产生死锁
3.1.5 引申
先看一下会打印什么,注意,这里对self.arr 进行了@synchronized 锁操作?
for (int i = 0; i < 100000; i++) { |
结果,会崩溃
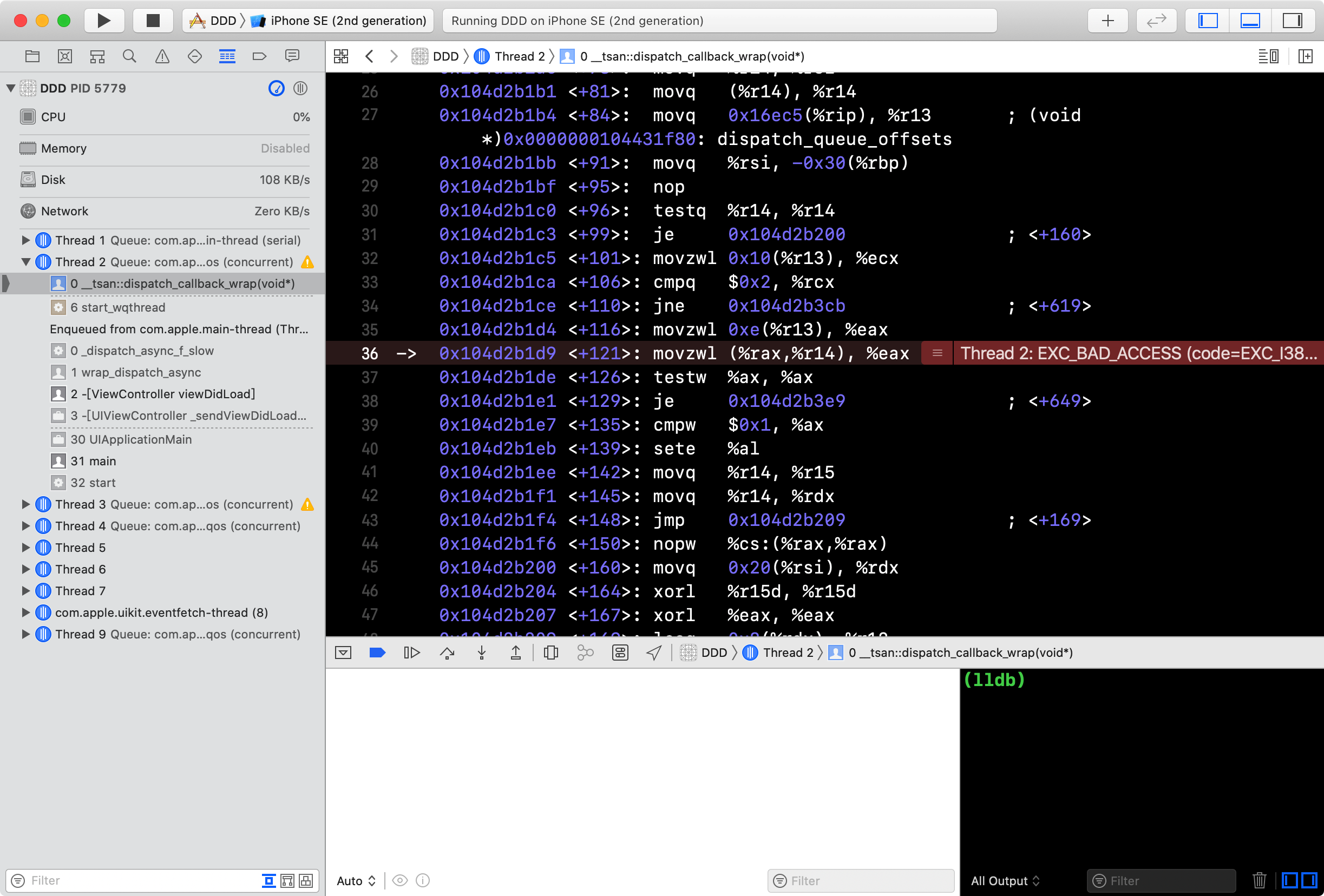
为什么,注意到这个可变数组 self.arr 一直属于 nil,那上文源码中得知:
// @synchronizedd(nil) does nothing |
即去锁一个空对象,是不会有锁操作,反而会报错崩溃。
解决
解决方案也简单:
对self 进行同步锁,这个似乎太臃肿了
也可以使用引入NSLock 进行锁定,如下操作:
for (int i = 0; i < 100000; i++) { |
下面来分析一下NSLock
3.2 互斥锁 - NSLock 的分析
大家都知道OC 中Foundation 并没有开源,所以无从查看NSLock 的实现,但是Swift 对Foundation 却开源了, 我们不妨曲线救国,在Swift 中一探究竟。相关Swift Foundation的源码可以在苹果的Github仓库 下载
3.2.1 创建
类的生成
open class NSLock: NSObject, NSLocking {
// 内部私有的互斥锁,容量创建为1
internal var mutex = _MutexPointer.allocate(capacity: 1)公用的
init方法如下:public override init() {
pthread_mutex_init(mutex, nil)
#if os(macOS) || os(iOS)
pthread_cond_init(timeoutCond, nil)
pthread_mutex_init(timeoutMutex, nil)
#endif
#endif
}可见,这个类的初始化,对内部的
pthread_mutex_init进行了操作,初始化局部变量互斥锁mutex
3.2.2 加锁
加锁的过程很简单,就是对内部这个互斥锁加锁
open func lock() { |
这里使用的是常见的pthread_mutex_lock 函数用来操作互斥锁。这里的问题是,如果mutex 当前被锁住,执行函数,会让当前线程阻塞,直到mutex状态改变为可以执行位置。
在这种情况下,大胆的猜测一下,当多次调用NSLock 的lock 方法时(递归),会反复调用mutex,造成锁等待,谁也开不了谁,最终线程阻塞,影响性能。
可见 NSLock 虽好,可以有造成线程阻塞的风险,尤其是进行递归循环的时候。
3.2.3 解锁
open func unlock() { |
解锁时,会对当前的mutex 进行解锁,以及超时解锁(使用)
3.3 递归锁与互斥锁区别
3.3.4 阻塞分析及解决
提问:下面会打印什么:
- (void)showLock{ |
结果会不会是 5-1 =4 ? 看一下打印如下:
2020-05-22 17:39:13.720485+0800 DDD[7989:543814] 加锁🔐 |
记过很残酷,block 只进行到第一个 NSLog 就不走了,第二个NSLog 都不再走了。
原因:递归调用普通的互斥锁,会造成线程阻塞(因为不会查询缓存)。block 反复调用自身block,都走不到
解决:使用递归锁 NSCursiveLock 替换 NSLock
即代码为:
- (void)showLock{ |
打印结果如下:
2020-05-22 17:51:20.645879+0800 DDD[8048:551083] 加锁🔐 |
此时不再阻塞,递归锁顺利完成了任务
内部实现:继续在Swift Foundation 查看NSRecursiveLock 的实现,结果如下:
withUnsafeMutablePointer(to: &attrib) { attrs in |
可见同 NSLock 类似,它的实现是调用pthread_mutexattr_settype 函数,并且类型为PTHREAD_MUTEX_RECURSIVE
3.3.2 递归锁的死锁
还是上面的例子,加一个for 循环,结果会如何呢?
- (void)showLock{ |
结果很残酷,是这样的,又崩溃了(为什么要说又呢😿)
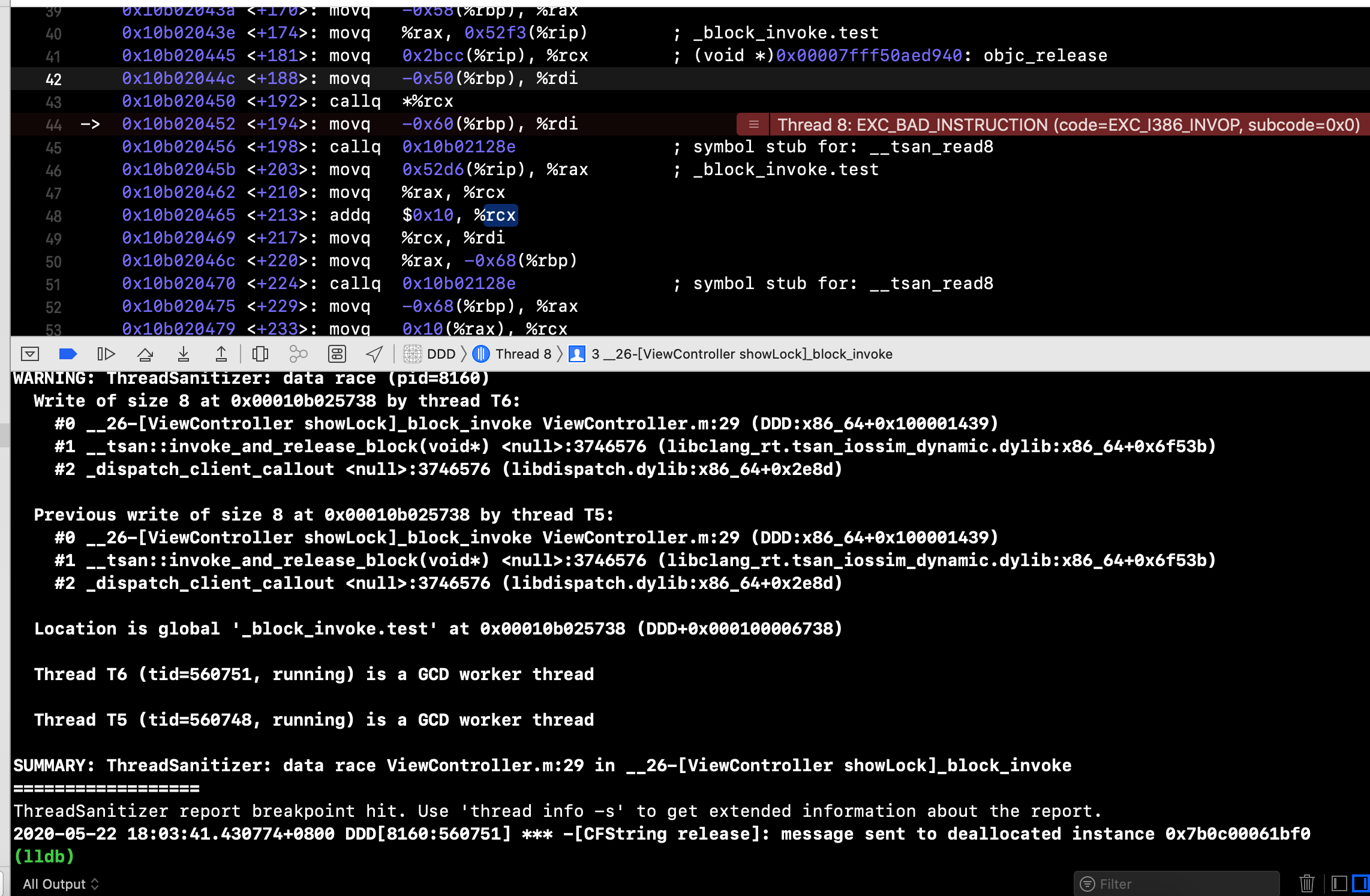
提示很明显,最后一行String release 释放一个野指针。。。
原因: for 循环在block 内部,对同一个对象进行了多次锁操作,最后大家都锁了一次,直到这个资源身上挂着N把锁,最后大家都无法一次性解锁——找不到解锁的出口 。
即 操作1-> 加锁1-> 加锁2-> 操作1结束 -(有2的锁)- 无法结束解锁——形成死锁
**解决:**可以采用使用缓存的@synchronized ,因为它对对象进行所操作,会先从缓存查找是否有锁syncData 存在,如果有,直接返回而不加锁,保证锁的唯一性。
操作如下:
- (void)showLock{ |
结果:也很和谐如下:
2020-05-22 18:17:02.225527+0800 DDD[8255:571494] 加锁🔐 |
3.3.3 递归锁内部区别
- @synchronized 采用缓存机制,不会造成死锁
- NSRecursiveLock 异步循环调用时,会造成多次加锁,造成死锁
3.3.4 应用场景
- 普通场景下,涉及到安全,可以用NSLock
- 循环调用时用 NSRecursiveLock
- 循环调用时,如果要注意死锁,建议使用 @synchronized
3.4 条件锁分析
A、NSCondiction
实际上作为一个锁和一个线程检查器:锁主要为了当检测条件时保护数据源,执行条件引发的任务;县城检查其主要是根据条件决定是否运行线程,即线程是否被阻塞。
执行起来,主要有4个步骤
[condition lock]: 一般用于多线程同时访问、修改同一个数据源,保证在同一时间内数据原只被访问、修改一次,其他线程的命令需要在lock外等待,直到unlock才可以访问[condition unlock]: 与lock同时使用[condition wait]; 让当前线程处于等待状态[condition signal]: CPU发信号高速县城不用再等待,可以继续执行了
B、NSConditionLock
是一种锁,一旦一个线程获得锁,其他线程一定等待。
主要有如下几个步骤:
[lock lock]: 标识lock 期待获得锁,如果没有其他线程获得锁(此时不需要判断内部condition)那他能执行以下代码,如果已经有其他线程获得锁(可能是条件锁,或者无条件锁),则等待,知道其他线程解锁。[lock lockWhenCondition: A]: 表示如果没有其它线程获得该锁,但是所内部的condition不等于条件A,他依然不能获得锁,仍然等待。如果内部的condition等于条件A,并且没有其他线程获得该锁,则进入代码区,同时设置他获得该锁,其他任何线程都将等待它的代码完成,直至它解锁。[lock unlockWhenCondition: A]:表示释放锁,同时把内部的condition 设置为A条件。return [xxx lockWhenCondition: A before: B]表示如果锁定(没获得锁),并超过该时间则不再阻塞线程。但是需要注意的是:返回值是NO,它没有改变锁的状态,这个函数的目的在于可以实现两种状态下的处理。
总结一下:所谓的condition(状态值)是证书,内部通过整数来比较条件。



