一、定义
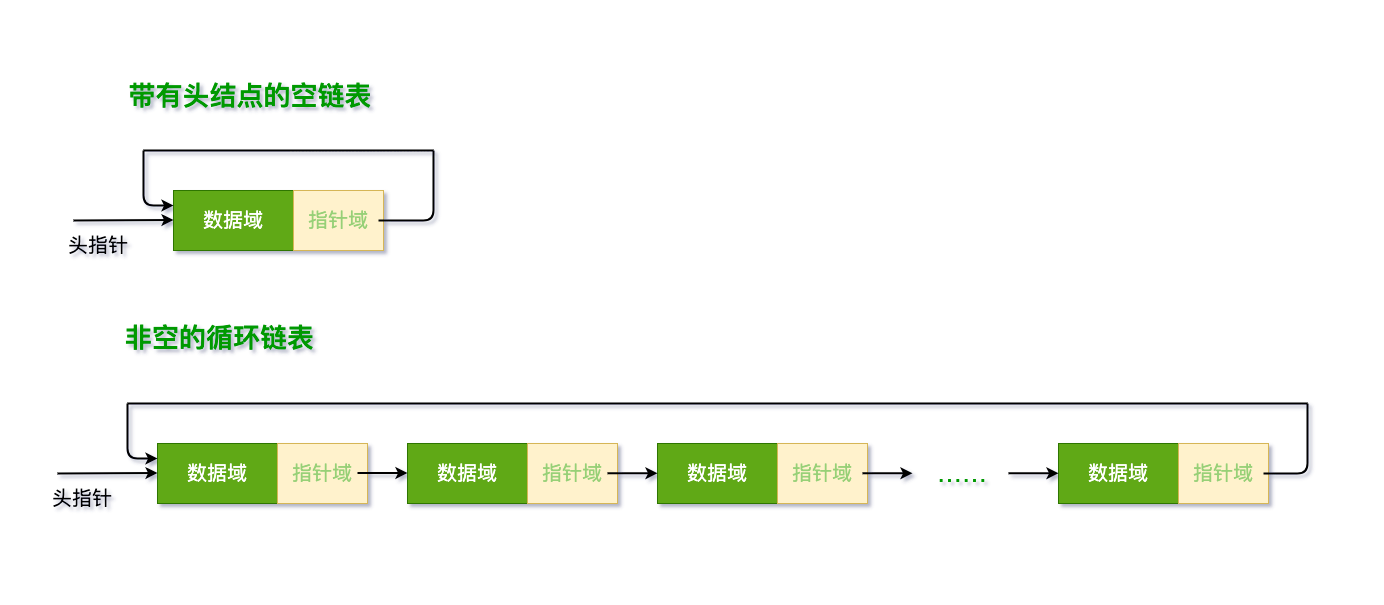
将单链表中终点结点的指针端由空指针改为指向头结点,就使整个单链表形成一个环,这种头尾相连的单链表称为单循环链表,简称循环链表(circular linked list)。
我们先讨论的是单向循环链表,示意图如下所示:
二、操作
2.1 创建单向循环链表
创建逻辑主要有下面的步骤:
先判断是否第一次创建?
- 是(空链表):创建一个结点,使新结点next 指向自身
- 否:使尾节点的next=新节点。新节点的next指向头节点
下面用代码解释一下:
- 先定义一个结点(结构体),定一个别名:
//定义结点 |
- 创建一些变量,以供环境使用:
Status CreateList(LinkList *L){ |
- 接下来判断这个链表
*L是否为空:
if(*L==NULL) |
- 如果输入的链表是空的——则创建一个结点,使它的
next指向自己:
Status CreateList(LinkList *L){ |
- 如果链表不为空——则去寻找链表的尾结点。
这里寻找尾结点可以有两种实现方式:
遍历尾结点,根据尾结点指针会指向首元结点来定位到尾结点。
- 1、使得尾结点的next 指向新结点。
- 2、新结点的next 指向头结点。
else{
for (target = *L; target->next != *L; target = target->next);
// 为新结点开辟内存空间
temp=(LinkList)malloc(sizeof(Node));
// 如开辟失败,返回错误
if(!temp) return ERROR;
// 新结点写入数据
temp->data=item;
temp->next=*L; //新节点指向头节点
target->next=temp;//尾节点指向新节点
}创建一个工具结点
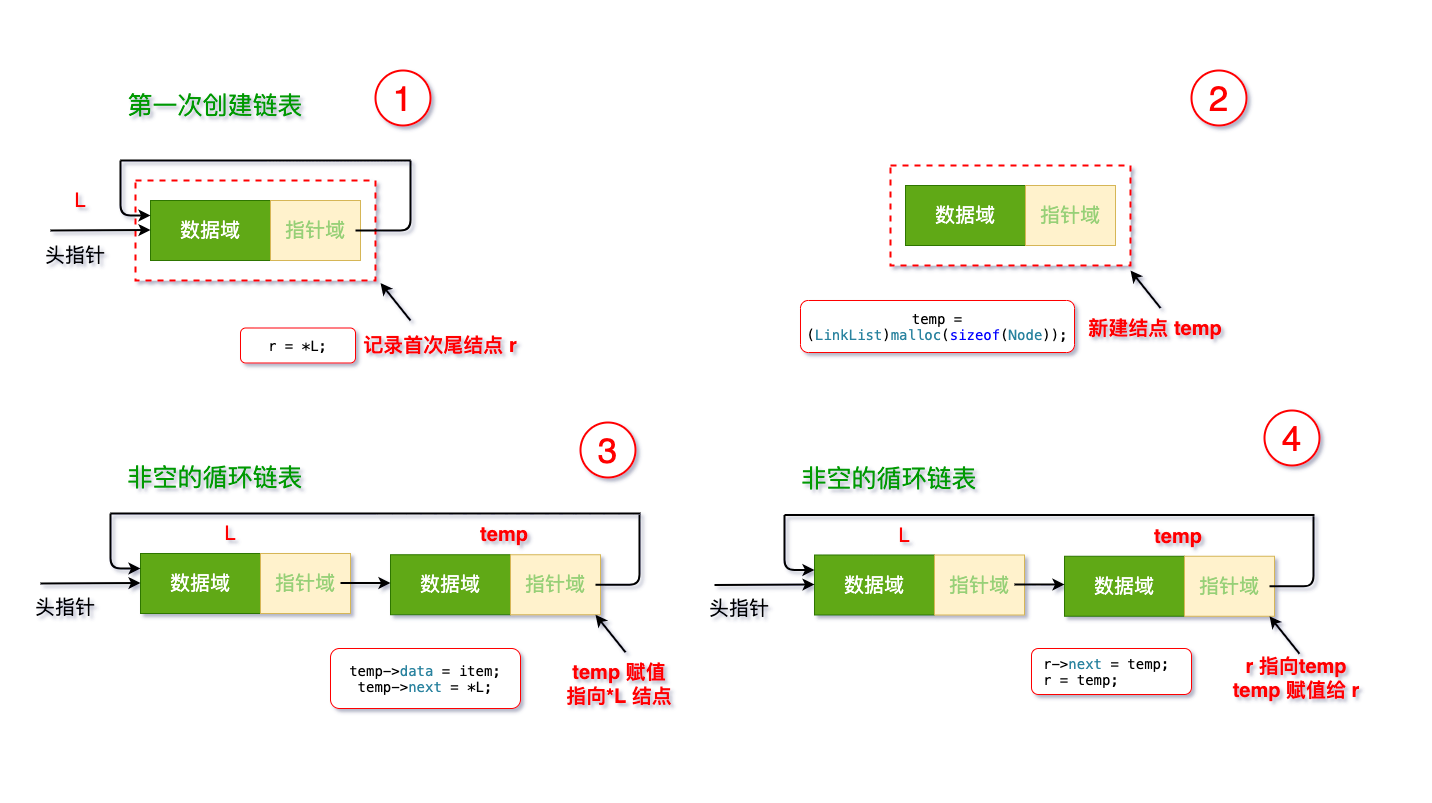
r,用它来灵活处理以后一个结点(后插法)
1. 新建一个 `r`
LinkList r = NULL;
2. 在该链表创建时,将唯一的结点赋值给`r`
//第一次创建
if(*L == NULL){
*L = (LinkList)malloc(sizeof(Node));
if(!*L) return ERROR;
(*L)->data = item;
(*L)->next = *L;
r = *L;
3. 创建新的结点,进行赋值,`next`指向原链表首结点
temp = (LinkList)malloc(sizeof(Node));
if(!temp) return ERROR;
temp->data = item;
temp->next = *L;
4. 把原最后一个结点的尾结点指向新结点,以及新结点赋值给工具结点`r`
r->next = temp;
这样,闭环完成,整个过程示意图可以用下面的图实现:
2.2 单向循环链表插入数据
分两种情况,插入点是否为首元结点
2.2.1 插入点位首元结点
- 创建新结点并进行赋值
- 找到链表最后的结点——尾结点
- 让新结点的
next指向头结点 - 让尾结点的
next指向新的头结点 - 让头结点指向
temp——临时的新结点
具体代码实现如下:
temp = (LinkList)malloc(sizeof(Node)); |
如图所示: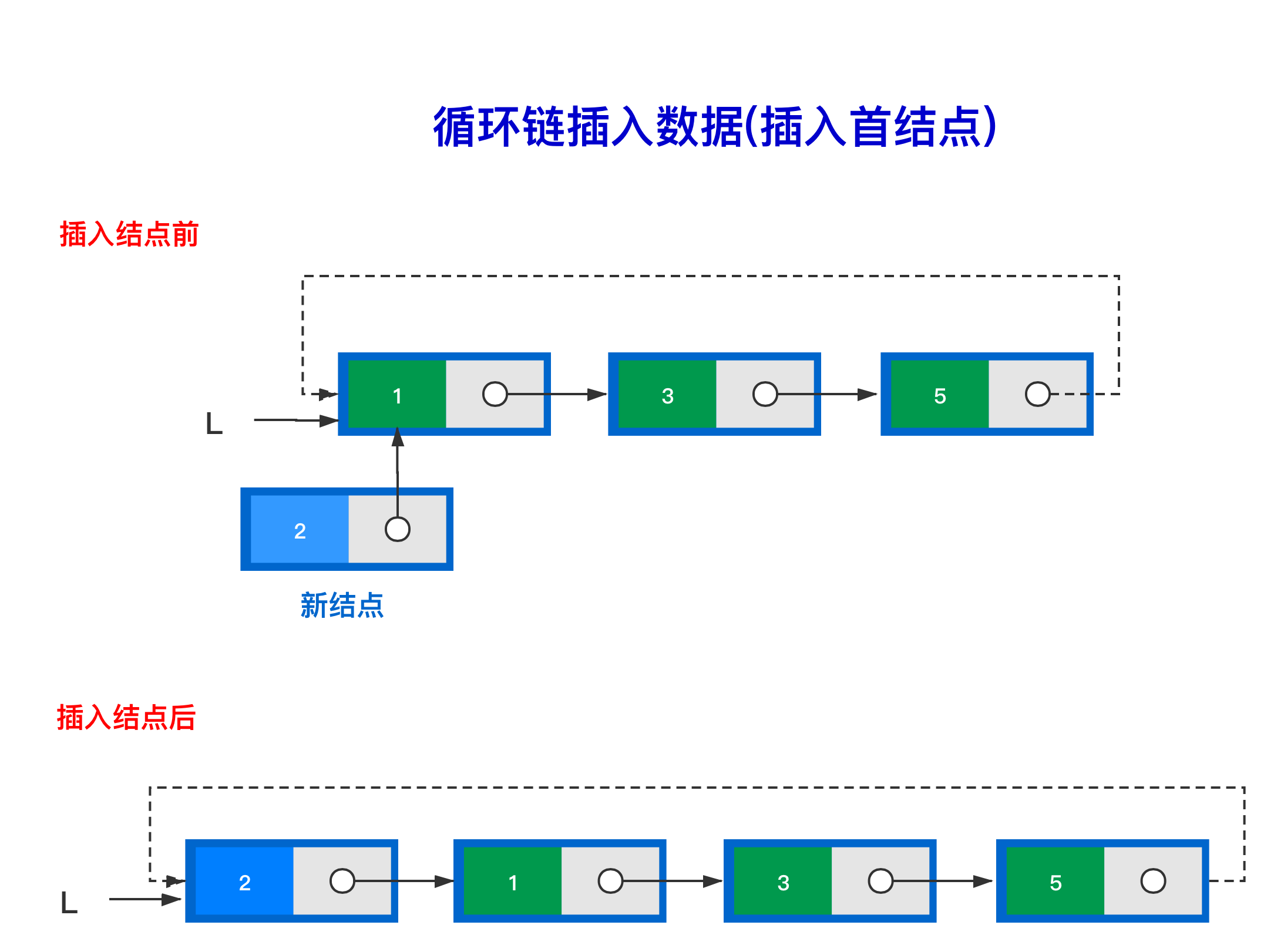
2.2.2 插入点非首元结点
- 创建新结点
temp,并判断成功与否 - 找到插入的位置,如果超过链表长度,则自动插入队尾
- 通过工具
target找到要插入位置的前一个结点,让target->next = temp - 插入结点的前一个结点
next指向新结点,新结点next指向target原来的next 位
具体代码实现如下:
temp = (LinkList)malloc(sizeof(Node)); |
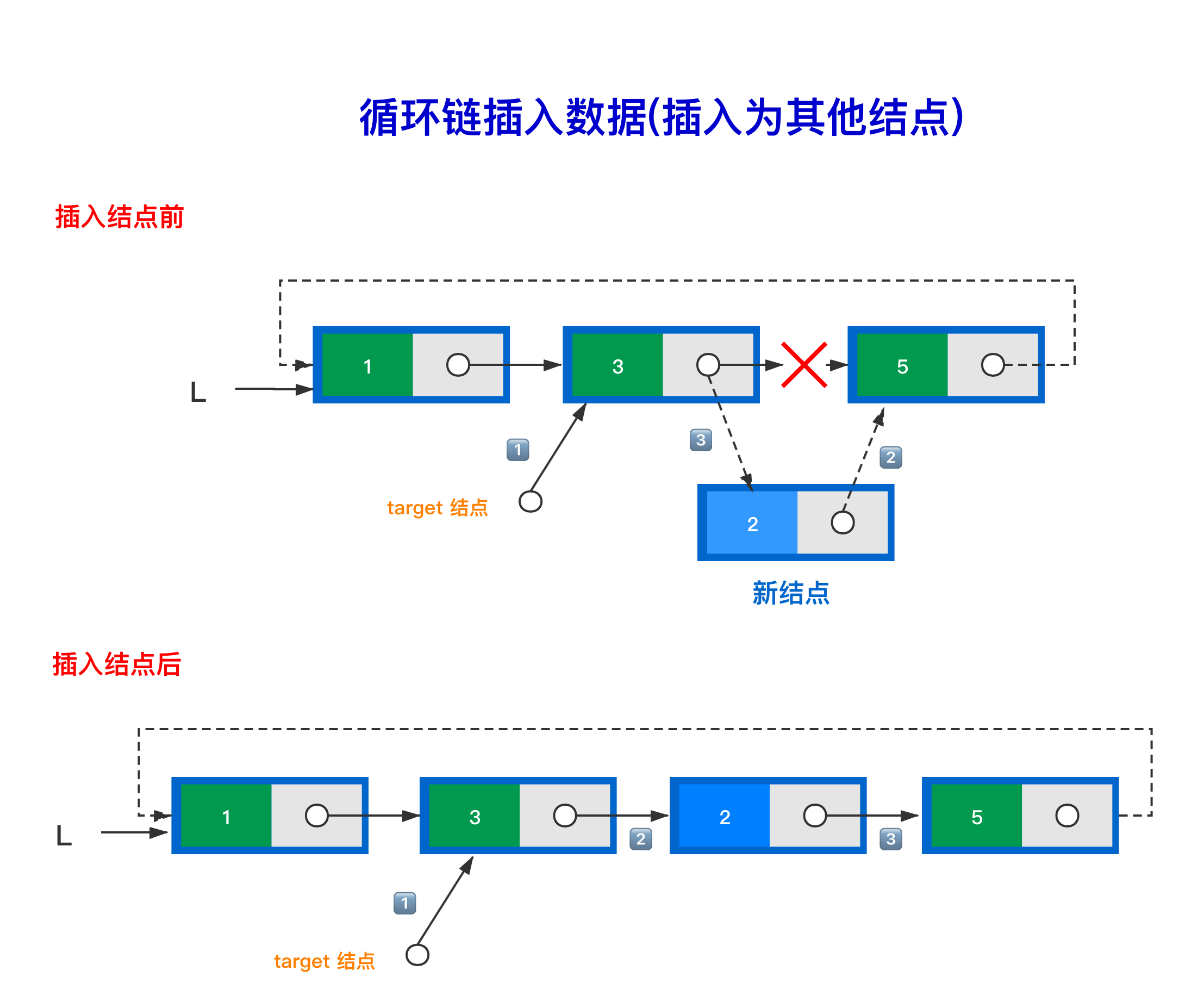
2.3 单向循环链表的删除
单向循环链表的删除,与顺序表的删除很类似,步骤都是先确定需要删除的位置,通过判断是否首元结点,做不同的操作。具体操作步骤如下:
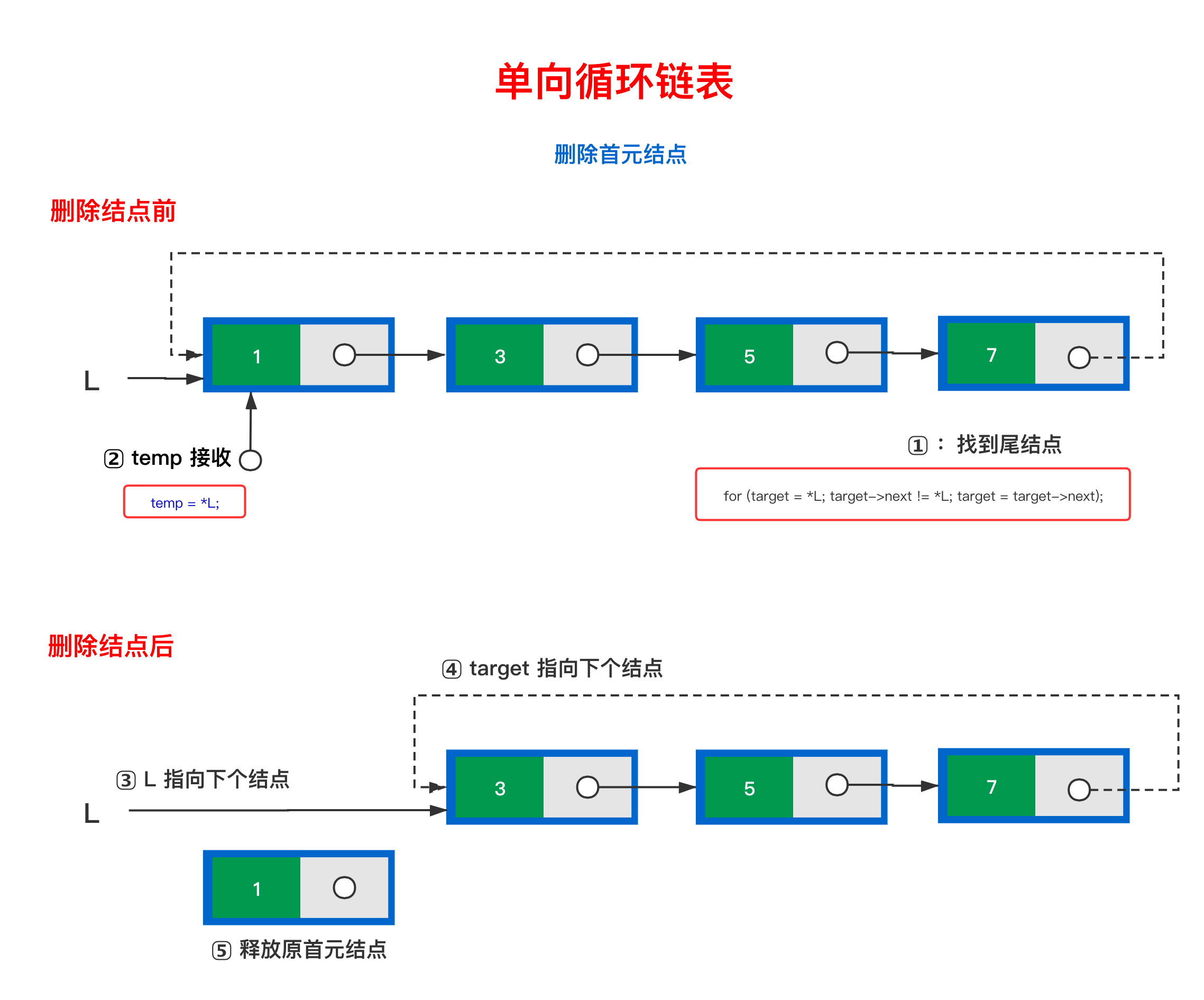
2.3.1 删除点为首元结点
如果本链表只剩首元结点,则直接将*L 置为空;
实施代码如下:
if((*L)->next == (*L)){
(*L) = NULL;
return OK;
}如果本链表还剩其他结点
- 找到尾结点
target - 尾结点
next指向原来首元结点的下一个结点,即target->next = (*L)->next - 用
temp临时接收首元结点 - 新结点为首元结点
- 释放之前的接收的首元结点
temp
实施代码如下:
// 步骤 1⃣️
for (target = *L; target->next != *L; target = target->next);
// 步骤 2⃣️
temp = *L;
// 步骤 3⃣️
*L = (*L)->next;
// 步骤 4⃣️
target->next = *L;
// 步骤 5⃣️
free(temp);- 找到尾结点
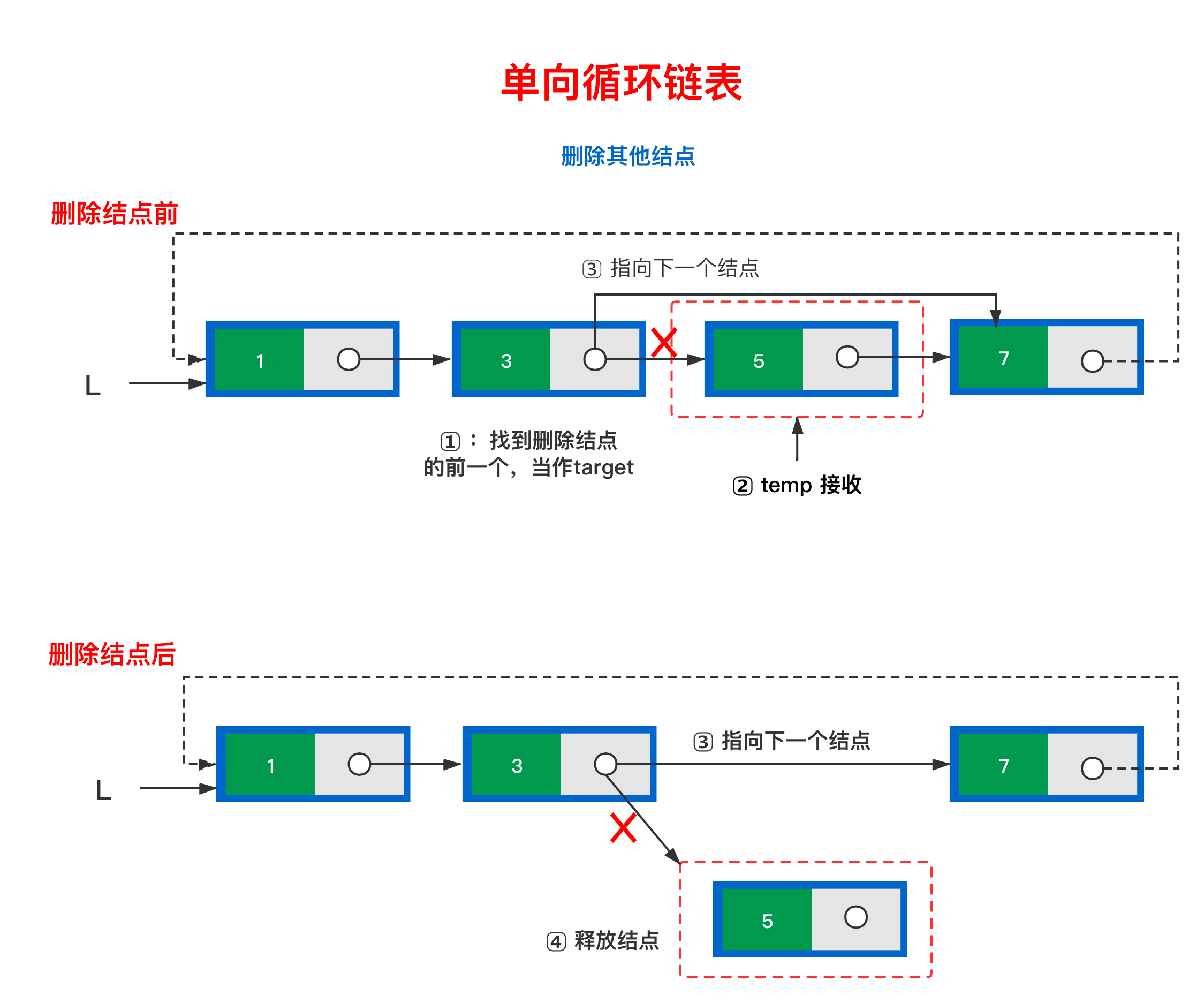
2.3.2 删除点为非首元结点
- 找到需要删除结点的上一个结点,用
target表示 - 用
temp临时接受需要删除的结点 target的next指之前指向的下一个结点- 释放
temp结点
实施代码如下:
// 步骤 1⃣️ |
示意图如下:
2.4 单向链表的查询
这里仅仅讨论下简单的链表查询,步骤如下:
- 循环查找链表中给定值的结点
- 若查询的结点指向首元结点,并且此时尾结点值也不为所需,跳出
实施代码如下:
int i = 1; |
三、小结
单向循环链表与顺序表有些许相似,但是不同点在于,它并非是按照序号排列,而是通过指针的指向进行连接,而且有首尾相连的特点。


