一、概念
双向链表:
是在单链表的每个节点中,再设置一个指向其前驱结点的指针域。
所以在双向链表中的结点有两个指针域,一个指向直接后继,另一个指向直接前驱。
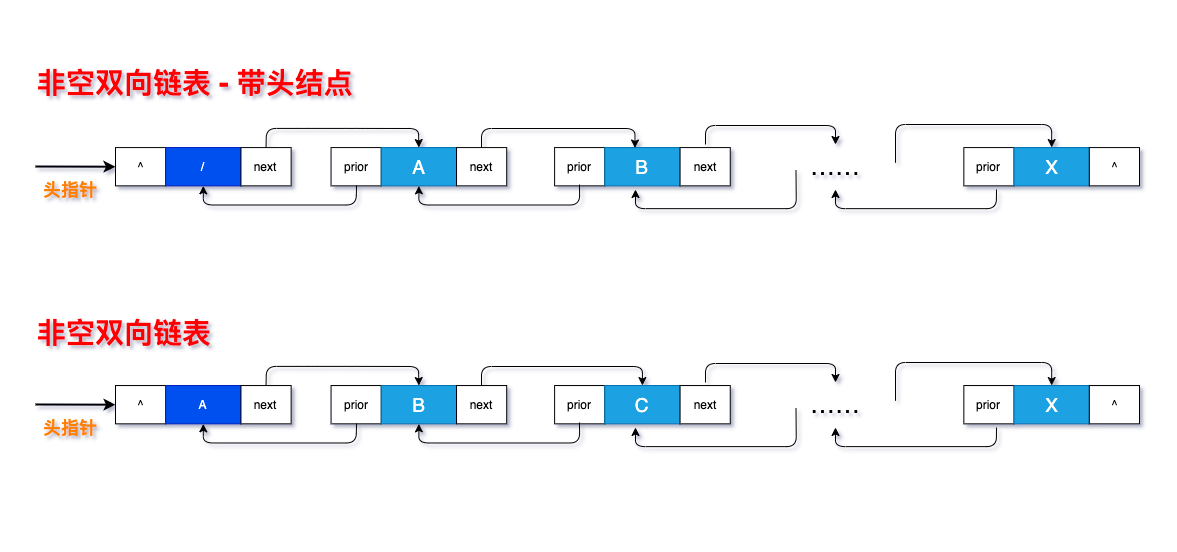
双向循环链表:
与双向链表相比,双向循环链表的尾结点的next指向头结点,头结点的prior 指向尾结点,形成一个循环。如下图所示:
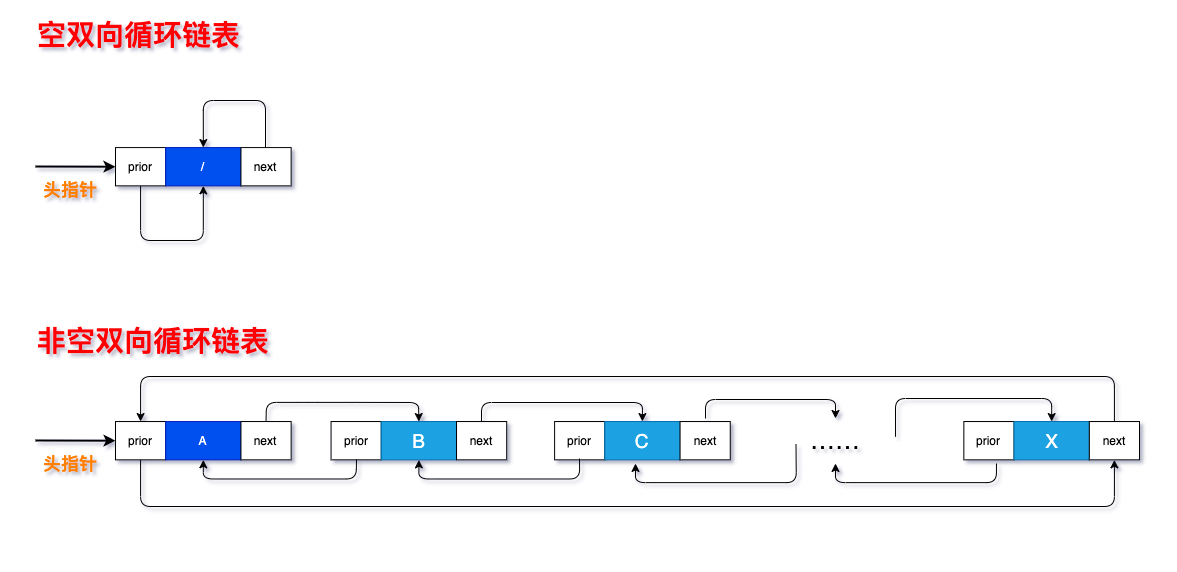
创建代码如下:
|
二、双向链表的操作
2.1 创建链表
创建双向链表的步骤如下:
- 创建空链表
L,以及结点*L - 指定一个尾结点为
p - 创建临时结点
temp,并进行数值给定 - 将当前尾结点
p与temp进行双线链接链接temp是p的后继p是temp的前驱
- 将
temp赋值给p,p依然为链表的尾结点。
// ① 创建*L 指向头结点 |
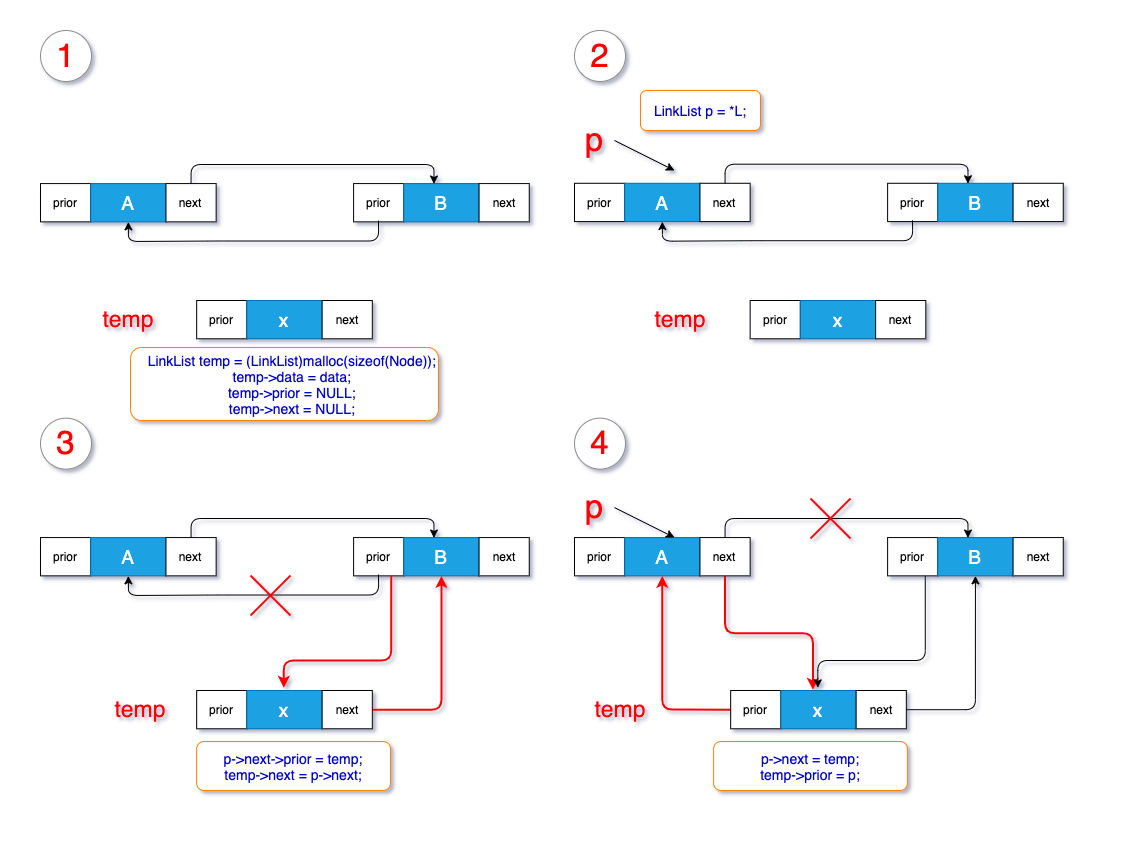
2.2 增加结点
向双向链表种添加结点的步骤和单向链表添加结点类似,只是多了一步链接前驱的工作。
步骤如下:
- 新建目标结点
temp - 创建指针
p,指向链表的头结点 - 通过循环便利,将
p向后移,找到插入位置i的结点- 【判断】如果插入位置超出链表本身长度,跳出
- 【判断】如果
p为链表尾部,只需做p与temp首尾相连
- 找到
i结点后,分两步对p与temp进行首尾相连- 将原
p的next的 prior 指向 目标结点temp - 将目标结点的
next指向p的next - 将
p的next指向目标结点temp - 将 目标结点
temp的prior指向p
- 将原
注意:这里的第四步中,第1,2两步必须先于3,4两步执行,否则先将p 与 temp,关联上,会导致原p 的next 丢失,成为野指针。
画个图表示一下流程:
Status ListInsert(LinkList *L, int i, ElemType data){ |
2.3 删除结点
删除链表中的结点分两种:删除指定位置结点和删除指定元素的结点。其思路都是一致的,遍历链表中的元素,找到指定元素,并进行删除。主要流程与删除单向链表的逻辑类似,只是多了一个移除前驱结点的操作。
删除结点的通俗理解:就好比员工离职前,必要的一步就是工作交接,告诉大家接下来工作时谁来接手,锅该由谁来背,公司才能正常运行;否则你一拍屁股删库跑路了,公司可就热闹了,大家都抓瞎了,这样就乱套了。
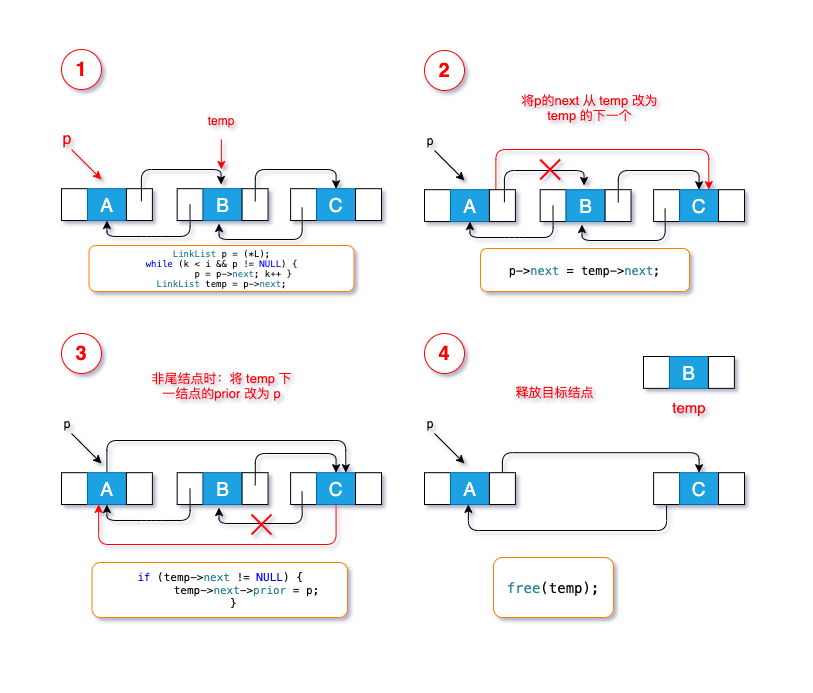
2.3.1 删除指定位置结点
流程如下:
- 给定一个工具结点
p,指向链表的头结点 - 依次循环查找,将
p指向删除位的前一个 - 创建临时结点
temp指向要删除的结点,并把该结点data赋值给返回的*e - 待删除结点上一结点的
next指向temp的后一个结点 - 待删除结点是否链尾结点?
- 并非链尾:将待删除结点
temp的下一结点的prior指向工具结点p - 是链尾:不作处理
- 并非链尾:将待删除结点
- 释放待删除结点
temp
总结一下,核心操作就两步:
- 将目标上一个结点的
next指给下一个 - 将目标的下一个结点的
prior指给上个结点
有图有真相:
贴一下实操的代码如下:
Status DeleteVeryNode(LinkList *L, int i, ElemType *e){ |
2.3.2 删除指定元素的结点
删除指定元素的结点,会更简单,只需要遍历循环,找到相应的结点后,依次对前驱点和后继点进行重新配置。
步骤如下:
- 创建链表
L, 将p指向首结点。 - 遍历链表
L,判断给定元素data与p-> data是否相等,相等即找到目标结点 - 修改目标结点的前驱结点的后继指针,指向目标结点下一个结点(交代后事….)
- 若删除结点非尾结点:修改目标结点后继结点的前驱指针
prior,指向目标的上一个结点。 - 释放被删除的结点
p
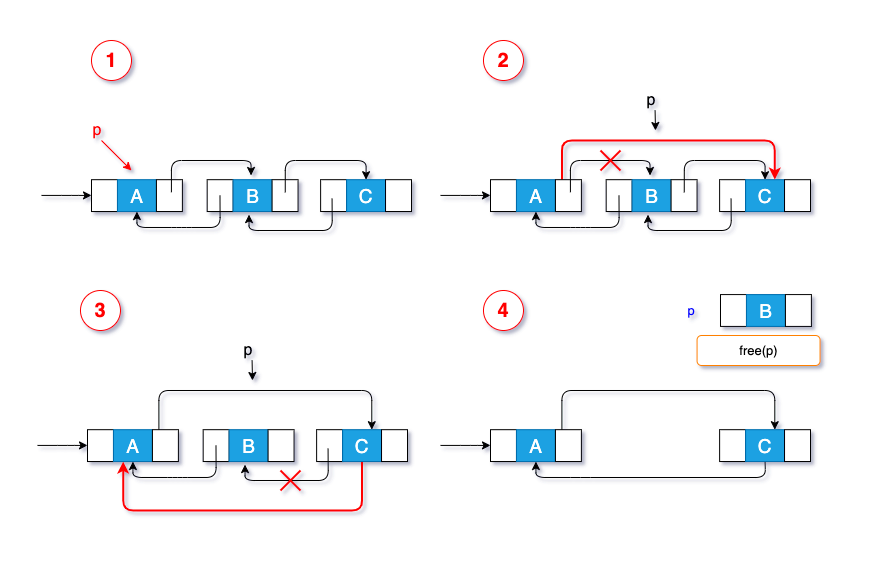
贴一下实操的代码如下:
Status DeleteDefinedNode(LinkList *L, int data){ |
2.4 查询结点
- 创建链表
L, 将p指向首结点。 - 遍历链表
L,判断给定元素data与p-> data是否相等,- 相等即找到目标结点,跳出。
- 否则继续循环,将
p移动到下一个结点
int selectElem(LinkList L,ElemType elem){ |
2. 5 更新结点
更新结点,只需要遍历循环链表,找到序号内的结点,将其数据域 data 替换为新的数据
Status replaceLinkList(LinkList *L,int index,ElemType newElem){ |
三、双向循环链表的操作
3.1 创建链表
双向循环链表的创建步骤,与双向链表类似。差别在于:多了将尾结点的 next 指向 头结点,而头结点的 prior 指向 尾结点。
具体步骤:
- 创建空链表
L,以及结点*L,使得其前驱和后继都指向自己 - 指定一个尾结点为
p - 创建临时结点
temp,并进行数值给定 - 将当前尾结点
p与temp进行双线链接链接temp是p的后继p是temp的前驱temp的后继是pp的前驱是新建的temp
- 将
temp赋值给p,p依然为链表的尾结点,方便下次插入新结点。
实现源码如下:
Status creatCircularLinkList(LinkList *L){ |
3.2 增加结点
与双向链表相似,区别在于双向循环链表由于有首位域,在找到指定位置后,需要先将插入结点的prior 和 next 与 前后建立关系,之后再考虑前结点的 next链接,最后考虑的是 目标结点的next
具体步骤如下:
- 新建目标结点
temp - 创建指针
p,指向链表的头结点 - 通过循环便利,将
p向后移,找到插入位置i的结点- 【判断】如果插入位置超出链表本身长度,跳出
- 【判断】如果
p为next指向 头结点跳出
- 找到
i结点后,分两步对p与temp进行首尾相连- 将
temp的prior指向p - 将
temp的next指向p的next - 将
p的next指向目标结点temp - 判断
temp是否是尾结点- 如果是:将头结点的
prior指向temp - 如果否:将目标结点
temp的prior指向p
- 如果是:将头结点的
- 将
Status LinkCircularListInsert(LinkList *L, int index, ElemType e){ |
3.3 删除结点
双向循环链表的结点删除,比双向链表的简单,因为链表首尾相连的特性,不需要考虑是否为尾结点或者头结点。
流程如下:
- 给定一个工具结点
p,指向链表的头结点 - 依次循环查找,将
p指向删除位的前一个 - 创建临时结点
temp指向要删除的结点,并把该结点data赋值给返回的*e - 待删除结点上一结点的
next指向temp的后一个结点 - 释放待删除结点
temp
总结一下,核心操作就两步:
- 将目标上一个结点的
next指给下一个 - 将目标的下一个结点的
prior指给上个结点
Status LinkListDelete(LinkList *L,int index,ElemType *e){ |
3.4 查询结点
与双向链表相同,更新结点,只需要遍历循环链表,找到序号内的结点,将其数据域 data 替换为新的数据
代码参见 2.5
四、总结
4.1 线性表结构
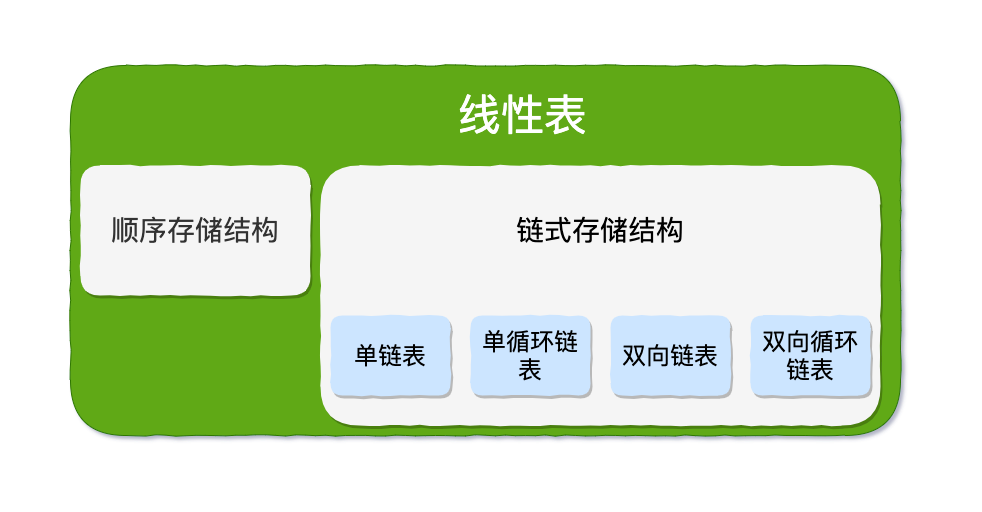
4.2 顺序表与链表比较
顺序结构的线性表与链式结构的线性表比较起来,
从空间性能上比较:
存储空间分配
存储密度的大小
存储密度 = $\frac{数据元素本身占用存储量}{结点结构占用的存储量}$
时间性能比较:
- 存储元素的效率
- 插入和删除操作的效率
4.3 其他
双向链表比起单向链表来说,增加了prior 这一指针域,可以在查找和删除时,极其迅速的操作,无须做更多的判断,极大地提高了运算效率。同时在操作时,需要注意指针修改顺序,以免形成野指针。



