去除重复字母
LeetCode 级别:困难
Q: 题目
给你一个仅包含小写字母的字符串,请你去除字符串中重复的字母,使得每个字母只出现一次。需保证返回结果的字典序最小。要求:不能打乱其他字符的相对位置。原题目leetcode链接
示例1:
输入:"bcabc"
输出:"abc"
示例2:
输入:"cbacdcbc"
输出:"acdb" ~~cbad~~, ~~bacd~~, ~~adcb~~
Analyze:
分析关键字:字典序、不打乱
- 字典序最小:即排列顺序按照26个字母一次排序,比如给的
antman肯定要排在ultraman前面 - 不打乱排序:即去除重复字母后,未被重复的那部分字母,不改变原来位置。比如
bcabc结果是abc那么去除的是第1、第2位的b和c, 后面3位abc依然不变。
A:思路:
给定字符串
s,排除字符串异常情况;使用一个
record数组,来记录字符串中字母出现的次数;创建一个栈
stack,用来存储去除重复字母的结果,并利用它的特性帮助我们找到正确的次序。遍历给定的字符串
s;从0~
top依次遍历stack,判断当前的字符s[i]是否存在于stack中,用一个int类型的值isExist来表示是否存在。如果
isExsit存在,即==1,将record [s[i]]位置上出现次数减1,即record[s[i]]--,并继续遍历下一个字符;意思是,当前的stack 已经包含这个字符,以后都不需要继续处理这个字符了。如果
isExist不存在,则需要while循环一下,找到这个字符正确的位置,然后存储起来。循环规则大概是这样:跳过栈中比当前字符大、而且后面还会出现的元素,将字符入栈。while循环的条件如下:- 用
top> -1 来保证栈不为空 - 用
stack[top]> s[i] 表示栈定元素比当前元素大 - 用
record[stack[top]]> 1 表示后面还会出现
- 用
等遍历完所有的字符后,对当前的字符栈
stack添加一个结束符\0,并返回当前字符串首地址;
代码实现
char *removeDuplicateLetters(char *s) |
试着执行一下代码:
char *s ; |
结果如下:
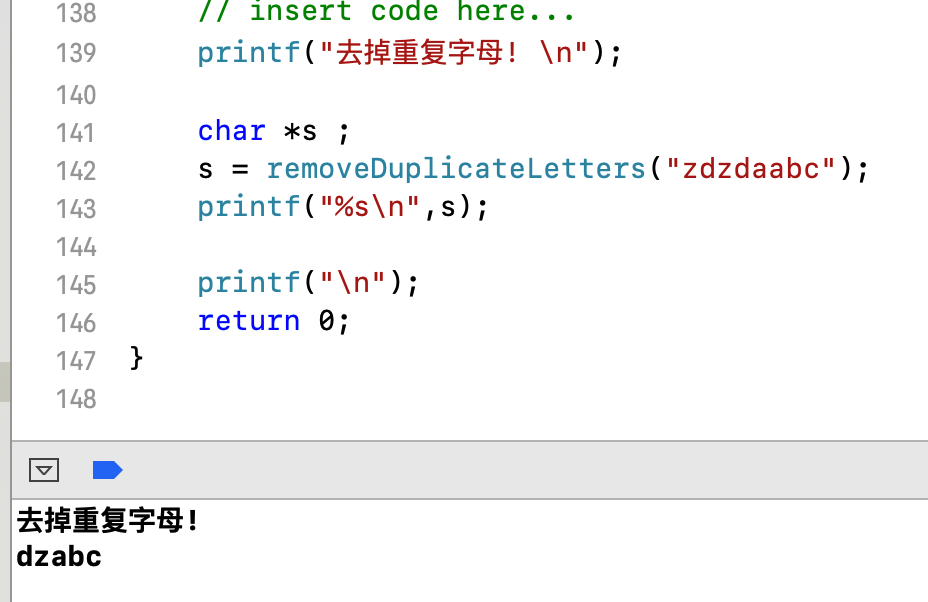
从 zdzdaabc = > dzabc ,符合要求 ✅
提交结果
leetcode 双百,可以可以




